Fast algorithms for fair packing and its dual
TL;DR: This is an informal summary of our recent article Fast Algorithms for Packing Proportional Fairness and its Dual by Francisco Criado, David Martínez-Rubio, and Sebastian Pokutta. In this article we present a distributed, accelerated and width-independent algorithm for the $1$-fair packing problem, which is the proportional fairness problem $\max_{x\in\mathbb{R}^n_{\geq 0}} \sum_i \log(x_i)$ under positive linear constraints, also known as the _packing proportional fairness_ problem. We improve over the previous best solution [DFO20] by means of acceleration. We also study the dual of this problem, and give a Multiplicative Weights (MW) based algorithm making use of the geometric particularities of the problem. Finally, we study a connection to the Yamnitsky-Levin simplices algorithm for general purpose linear feasibility and linear programming.
Written by Francisco Criado and David Martínez-Rubio.
Motivation: Proportional fairness
Consider a linear resource allocation problem with $n$ users:
\[\tag{packing} \begin{align} \max &\ \ u(x_1, \dots, x_n) \\ \nonumber s.t. \ \ & Ax\leq b \\ \nonumber &\ \ x\geq 0 &\ \ A \in \mathcal{M}_{m\times n}(\mathbb{R}_{\geq 0}) \end{align}\]Here the constraints are linear and non-negative (that is, $A, b \geq 0$), which can naturally happen for example if the resource has to be delivered via a network. We could set the utility $u(x_1,\dots, x_n)= \sum_{i\in [n]} x_i$ to maximize the total amount of the resource delivered. However, for some applications, this could be unfair. One of the users could get a proportionally small increase in their allocated resources at the cost of some other user getting completely ignored. The question is now what is a fairness measure we could use to quantify the fairness of the allocation?
Under some natural axiomatic assumptions (see [BF11] [LKCS10]), the most fair such allocation is the one maximizing the product of the allocations, or in other terms, $u(x_1,\dots, x_n)= \sum_{i\in[n]} \log x_i$. The solution maximizing this utility attains proportional fairness. This fairness criterion was first introduced by Nash [N50] and is consistent with the logarithmic utility commonly found in portfolio optimization problems as well.
This motivates our study of the problem
\[\tag{primal} \begin{align} \label{eq:primal_problem} \max &\ \ f(x)=\sum_{i\in [n]} \log x_i \\ \nonumber s.t. &\ \ Ax\leq \textbf{1} \\ \nonumber & \ \ x\geq \textbf{0} \end{align}\]This problem is equivalent to maximizing the product of coordinates over the feasible region \(\mathcal{P} = \{x \in \mathbb{R}: Ax\leq \textbf{1}, x\geq \textbf{0}\}\). Note we assume without loss of generality $b = \textbf{1}$ since we can divide each row of $A$ by $b_j$ to obtain such a formulation. We also assume wlog that the maximum entry of each column is $1$, i.e., $\max_{j\in[m]} A_{ij} =1$ for all $i \in [n]$, which can be obtained by rescaling the variables $x_j$ and corresponding columns of $A$. The latter only adds a constant to the objective.
A relevant quantity is the width of the matrix, which is the ratio between the maximum element of $A$ and the minimum nonzero element of $A$ and can be exponential in the input. [BNOT14] studied linearly constrained fairness problems with strongly concave utilities by applying an accelerated method to the dual problem and recovering a primal solution. Smoothness and Lipschitz constants of the former objectives do not scale poly-logarithmically with the width and thus, direct application of classical first-order methods lead to non-polynomial algorithms.
There is a more general fairness objective called $\alpha$-fair packing, for which packing proportional fairness corresponds to $\alpha=1$, packing linear programming results when $\alpha=0$ and the min-max fair allocation arises when $\alpha\to\infty$. [MSZ16] and [DFO20] studied this general setting and obtained algorithms with polylog dependence on the width (so the algorithms are polynomial). [MSZ16] focused on a stateless algorithm and [DFO20] obtained better convergence rates by forgoing the stateless property. For packing proportional fairness, the latter work obtained rates of $\widetilde{O}(n^2/\varepsilon^2)$. In contrast, our solution does not depend on the width and we obtain rates of $\widetilde{O}(n/\varepsilon)$ with an algorithm that is not stateless either. All these algorithms can work under a distributed model of computation that is natural in some applications [AK08]. In this model, there are $n$ agents and agent $j\in[n]$ has access to the $j$-th column of $A$ and to the slack $(Ax)_i -1$ of the constraints $i$ in which $j$ participates. The total work of an iteration is the number of non-zero entries of $A$, and is distributed across agents.
Our solution for the dual problem does not depend on the width either and it converges with rates $\widetilde{O}(n^2/\varepsilon)$. We interpret the dual objective as the log-volume of a simplex covering the feasible region, and we use this interpretation to present an application to the approximation of the simplex $\Delta^{(k+1)}$ of minimum volume that covers a polytope $\mathcal{P}$, where $\Delta^{(k+1)}$ is given by a previous bounding simplex $\Delta^{(k)}$ containing $\mathcal{P}$, and where exactly one facet is allowed to move. This results in some improvements to the old method of simplices algorithm by [YL82] for linear programming.
The primal problem
We designed a distributed accelerated algorithm for $1$-fair packing by using an accelerated technique that uses truncated gradients of a regularized objective, similarly to [AO19] for packing LP. However, in contrast, our algorithm and its guarantees are deterministic. Also, our algorithm makes use of a different regularization and an analysis that yields accelerated additive error guarantees as opposed to multiplicative ones. The regularization already appeared in [DFO20] with a different algorithm and analysis.
We reparametrize our objective function $f$, with optimum $f^\ast$ in Problem (primal), so that it becomes linear at the expense of making the constraints more complex. The optimization problem becomes
\[\max_{x\in \mathbb{R}^{n}}\left\{\hat{f} = \langle \mathbb{1}_{n}, x\rangle: A\exp(x) \leq \mathbb{1}_{m}\right\}.\]Then, we regularize the negative of the reparametrized objective by adding a fast-growing barrier, that we minimize in a box $\mathcal{B} = [-\omega, 0]^n$, for some value of $\omega$ chosen so that the optimizer must lie in the box. This redundant constraint is introduced to later guarantee a bound on the regret of the mirror descent method that runs within the algorithm. The final problem is:
\[\min_{x\in\mathcal{B}}\{f_r(x)= -\langle \mathbb{1}_{n}, x \rangle + \frac{\beta}{1+\beta}\sum_{i=1}^{m} (A\exp(x))_i^{\frac{1+\beta}{\beta}} \},\]for a parameter $\beta$ that is roughly $\varepsilon/(n\log(n/\varepsilon))$. This choice of $\beta$ makes the regularizer add a penalty of roughly $\varepsilon$ if $(A\exp(x))_i > 1+\varepsilon/n$, for some $i\in[n]$ and at the same time points satisfying the constraints and not too close to the border will have negligible penalty. This fact allows to show that it is enough to minimize $f_r$ defined as above in order to solve the original problem. The regularized function also satisfies that its gradient $\nabla f_r(x) \in [-1, \infty]^{n}$, so whenever a gradient coordinate is large, it is positive and this allows for taking a gradient step that decreases the function significantly. In particular, for a point $y^{(k)}$ obtained by a gradient step from $x^{(k)}$ with the right learning rate we can show
\[f_r(x^{(k)}) -f_r(y^{(k)}) \geq \frac{1}{2}\langle \nabla f_r(x^{(k)}), x^{(k)}-y^{(k)}\rangle \geq 0.\]This is a smoothness-like property that we exploit in combination with the mirror descent that runs with truncated losses, in order to use a linear coupling [AO17] argument to obtain an accelerated deterministic algorithm. In short, the local smoothness of the function $f_r$ is large, so instead of feeding the gradient to mirror descent and obtain a regret of the order of $|\nabla f(x)|^2$ , we run a mirror descent algorithm with losses $\ell_k$ equal to $\nabla f(x^{(k)})$ but clipped so each coordinate is in $[-1, 1]$. Then, we couple this mirror descent with the gradient descent above and show the progress of the latter compensates for the regret of the mirror descent step and for the part of the regret we ignored when truncating the losses, i.e. for $\langle \nabla f_r(x^{(k)})-\ell_k, z^{(k)}-x_r^\ast \rangle$ where $z^{(k)}$ is the mirror point and $x_r^\ast$ is the minimizer of $f_r$
After a careful choice of learning rates $\eta_k$, coupling parameter $\tau$, box width $\omega$, parameter $L$ and number of iterations $T$ (that are computed given the known quantities $\varepsilon$ and $A \in \mathbb{R}^{m\times n}_{\geq 0}$), the final algorithm has a simple form as a linear coupling algorithm that runs in $T = \widetilde{O}(n/\varepsilon)$ iterations.
Accelerated descent method for 1-fair packing
Input: Normalized matrix $A \in \mathbb{R}^{m\times n}_{\geq 0}$ and accuracy $\varepsilon$.
- $x^{(0)} \gets y^{(0)} \gets z^{(0)} \gets -\omega \textbf{1}_n$
- for $k = 1$ to $T$
- $x^{(k)} \gets \tau z^{(k-1)} + (1-\tau) y^{(k-1)}$
- $z^{(k)} \gets \operatorname{argmin}_{z\in \mathcal{B}}\left( \frac{1}{2\omega}\mid\mid z-z^{(k-1)}\mid\mid_2^2 + \langle \eta_k\ell_k(x), z\rangle \right)$ (Mirror descent step)
- $y^{(k)} \gets x^{(k)} + \frac{1}{\eta_k L}(z^{(k)}-z^{(k-1)})$ (Gradient descent step)
- end for
- return $\widehat{x} \stackrel{\mathrm{\scriptscriptstyle def}}{=} \exp(y^{(T)})/(1+\varepsilon/n)$
The dual problem
Now let us look at the Lagrangian dual of (primal):
\[\tag{dual} \begin{align} \label{eq:dual_problem} \max &\ \ g(\lambda)=-\sum_{i\in [n]} \log (A^T\lambda)_i \\ \nonumber s.t. &\ \ \lambda\in \Delta^m \end{align}\]Here $\Delta^m$ is the standard probability simplex, that is, $\sum_{i\in [m]} \lambda_i=1$, $\lambda\geq \textbf{0}$. Recall that the feasible region of (primal) was the positive polyhedron $\mathcal{P}$. In the dual, we study the dual feasible region \(\mathcal{D}^+ = \{A^T \lambda + \mu : \lambda \in \Delta^m, \mu\in \mathbb{R}_{\geq 0}^n \}\). It turns out that $\mathcal{D}^+$ is exactly the set of vectors $h \in \mathbb{R}_{\geq 0}$ such that $\langle h, x\rangle \leq 1$ for all $x\in \mathcal{P}$.
In other words, $\mathcal{D}^+$ is the set of positive constraints covering $\mathcal{P}$, if we represent the halfspace \(\{x\in\mathbb{R}_{\geq 0} : \langle h,x \rangle \leq 1 \}\) by the vector $h$. $\mathcal{D}^+$ contains also the related polytope \(\mathcal{D}=\{ A^T \lambda : \lambda \in \Delta^m \}\). Problem (dual) actually optimizes over $\mathcal{D}$ but it can be shown that by expanding the feasible region to $\mathcal{D}^+$ the optimum does not change. A crucial observation for later is that if $\lambda^{opt}$ is the optimum of (dual), then $A^T \lambda^{opt}$ is the half space covering $\mathcal{P}$ minimizing the volume of the simplex it encloses with the first orthant.
Now, consider the following map from $\mathcal{D}^+ \rightarrow \mathbb{R}_{\geq 0}$:
\[c(h) = \left( \frac{1}{nh_1}, \dots, \frac{1}{nh_n}\right).\]We call this map the centroid map, as it maps the hyperplane $H={x\in\mathbb{R}_{\geq 0} : \langle h, x \rangle = 1 }$ to the centroid (barycenter) of the simplex formed by its intersection with the positive orthant.
The primal and dual problems are related by this centroid map: if $x^{opt}$ is the optimum of (primal) and $\lambda^{opt}$ is the optimum of (dual) (both problems have an unique solution because of strong convexity), then $x^{opt} = c(A^T \lambda^{opt})$.
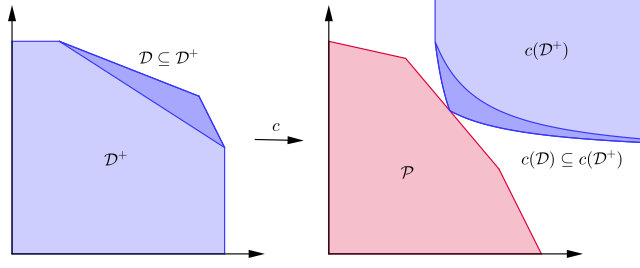
Figure 1. The centroid map.
This means the primal optimum is the unique point in the intersection $\mathcal{P} \cap \mathcal{D}^+$. $c(\mathcal{D}^+)$ is convex, so this is a linear feasibility problem over a convex set. We use Plotkin-Smoys-Tardos (PST) for this problem, in a version inspired by [AHK12] which is better suited for this purpose.
The PST algorithm requires an oracle which for a given “query” halfspace $h$ returns a point $x\in c(\mathcal{D}^+)$ such that $\langle h, x\rangle \leq 1$. The closer the oracle returns points to the optimum $x^{opt}$, the faster our algorithm will run. The oracle we suggest depends on a feasible solution to (dual), and its performance improves as the solution is closer to optimum in (dual).
In particular, our oracle depends on a solution $s$ and the points it returns are in a region we call the lens of $s$, $\mathcal{L}_{\delta}$:
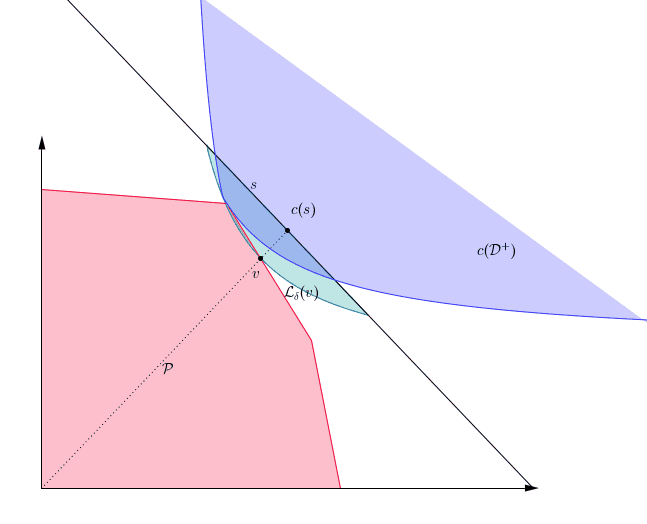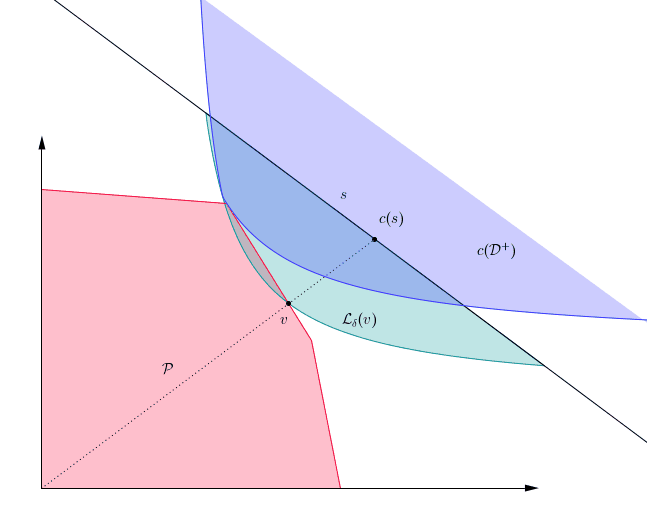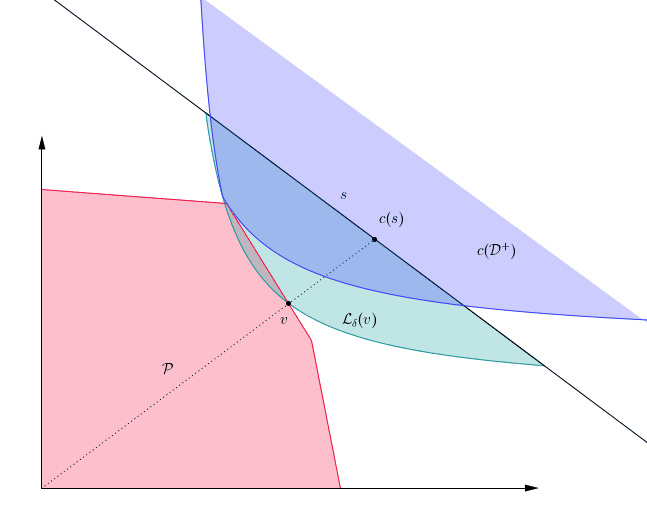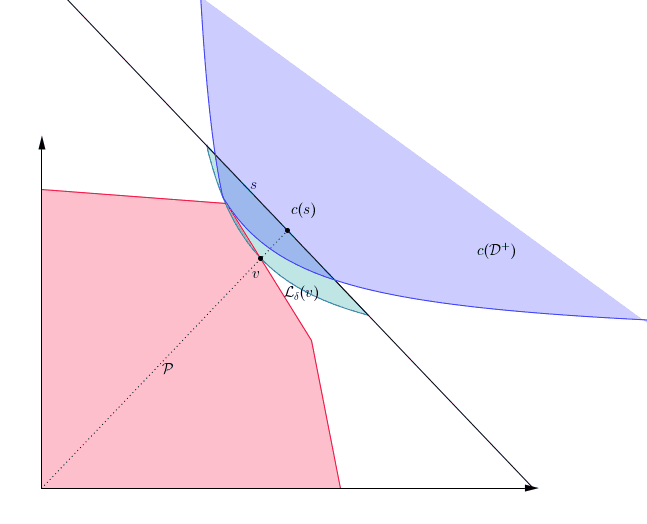
Figure 2. The primal polytope $P$, and the lens of a feasible solution.
As the figure illustrates, the lens of $s$ becomes smaller as $s$ improves as a solution. For this reason, we use a restart scheme: First we compute some approximate solution, then we use that approximate solution as the input for the oracle in the next restart. With this approach, we attain the following result:
Theorem 9. Let $\varepsilon \in (0,n(n-1)]$ be an accuracy parameter. There is an algorithm that finds a linear combination of the rows of $A$, $\lambda\in\Delta^m$ such that $g(\lambda)$ is an $(\varepsilon/n)$-approximate solution of (dual) after $\widetilde{O}( n^2/\varepsilon)$ iterations.
A potential application: The Yamnitsky-Levin simplices algorithm
The Yamnitsky-Levin algorithm [YL82] is an algorithm for linear feasibility problem. It is very similar to the ellipsoid method:
Input: A matrix $A\in\mathbb{R}^{m\times n}_{\geq 0}$,and a vector $b\in\mathbb{R}$
Output: Either a point $x\in\mathcal{P}$ where $P={x\in \mathbb{R}_{\geq 0} : Ax\leq b }$ or the guarantee that $\mathcal{P}$ has volume $\leq \varepsilon$.
- start with a simplex $\Delta$ covering $\mathcal{P}$.
- while the centroid of $\Delta$, $c$ is not in $\mathcal{P}$
- find a hyperplane separating $c$ from $\mathcal{P}$ (a row of $Ax\leq b$).
- Combine the separating hyperplane with $\Delta$ to find a new simplex $\Delta$ with smaller volume.
- return c
The interested reader can see the details in [YL82]. Observe that if we choose a suitable change of basis, we can map any $(d-1)$ facets of $\Delta$ to the first orthant. The Yamnitsky-Levin algorithm tries to find some hyperplane for the last facet minimizing the simplex volume while covering $\mathcal{P}$.
Recall that this is exactly what (dual) is, except we are only considering the positive constraints. In a way, (dual) is solving the Yamnitsky-Levin problem but with two changes: it considers more than one constraint at the same time, but it can only change one facet of the simplex at a time.
It is possible to replace the Yamnitsky-Levin simplex pivoting step with the algorithm in Theorem 9. However, it is not clear yet how this affects its performance.
We would like to thank Prof. Elias Koutsoupias for starting our motivation in this problem.
References
[AK08] Baruch Awerbuch and Rohit Khandekar. Stateless distributed gradient descent for positive linear programs. Proceedings of the fourtieth annual ACM symposium on Theory of computing - STOC 08, page 691, 2008
[AO17] Zeyuan Allen-Zhu and Lorenzo Orecchia. Linear coupling: An ultimate unification of gradient and mirror descent. In Christos H. Papadimitriou, editor, 8th Innovations in Theoretical Computer Science Conference, ITCS 2017, January 9-11, 2017, Berkeley, CA, USA, volume 67 of LIPIcs, pages 3:1–3:22. Schloss Dagstuhl - Leibniz-Zentrum für Informatik, 2017.
[AO19] Zeyuan Allen-Zhu and Lorenzo Orecchia. Nearly linear-time packing and covering LP solvers achieving width-independence and 1/epsilon-convergence. Math. Program., 175(1-2):307–353, 2019. doi: 10.1007/s10107-018-1244-x. URL https://doi.org/10.1007/s10107-018-1244-x.
[AHK12] Sanjeev Arora, Elad Hazan, and Satyen Kale. The multiplicative weights update method: a meta-algorithm and applications. Theory Comput., 8(1):121–164, 2012. doi: 10.4086/toc.2012. v008a006. URL https:// doi.org/ 10.4086/ toc.2012.v008a006.
[BF11] Dimitris Bertsimas, Vivek F. Farias, and Nikolaos Trichakis. The price of fairness. Oper. Res., 59 (1):17–31, 2011. doi: 10.1287/opre.1100.0865. URL https://doi.org/10.1287/opre.1100.0865.
[LKCS10] Tian Lan, David T. H. Kao, Mung Chiang, and Ashutosh Sabharwal. An axiomatic theory of fairness in network resource allocation. In INFOCOM 2010. 29th IEEE International Conference on Computer Communications, Joint Conference of the IEEE Computer and Communications Societies, 15-19 March 2010, San Diego, CA, USA, pages 1343–1351. IEEE, 2010. doi: 10.1109/ INFCOM.2010.5461911. URL https://doi.org/10.1109/INFCOM.2010.5461911.
[BNOT14] Amir Beck, Angelia Nedic, Asuman E. Ozdaglar, and Marc Teboulle. An $O(1/k)$ gradient method for network resource allocation problems. IEEE Trans. Control. Netw. Syst., 1(1):64–73, 2014. doi: 10.1109/TCNS.2014.2309751. URL https://doi.org/10.1109/TCNS.2014.2309751.
[MSZ16] Jelena Marašević, Clifford Stein, and Gil Zussman. A fast distributed stateless algorithm for alpha-fair packing problems. In Ioannis Chatzigiannakis, Michael Mitzenmacher, Yuval Rabani, and Davide Sangiorgi, editors, 43rd International Colloquium on Automata, Languages, and Programming, ICALP 2016, July 11-15, 2016, Rome, Italy, volume 55 of LIPIcs, pages 54:1–54:15. Schloss Dagstuhl - Leibniz-Zentrum für Informatik, 2016. doi: 10.4230/LIPIcs.ICALP.2016.54. URL https://doi.org/10.4230/LIPIcs.ICALP.2016.54.
[DFO20] Jelena Diakonikolas, Maryam Fazel, and Lorenzo Orecchia. Fair packing and covering on a relative scale. SIAM J. Optim., 30(4):3284–3314, 2020. doi: 10.1137/19M1288516. URL https://doi.org/10.1137/19M1288516.
[N50] John F. Nash. The bargaining problem. Econometrica, 18(2):155–162, 1950. ISSN 00129682, 14680262. URL http://www.jstor.org/stable/1907266.
[YL82] Boris Yamnitsky and Leonid A. Levin. An old linear programming algorithm runs in polynomial time. In 23rd Annual Symposium on Foundations of Computer Science, Chicago, Illinois, USA, 3-5 November 1982, pages 327–328. IEEE Computer Society, 1982.
Comments